一
1
SELECT city,count FROM 表名
2
models.User.objects.filter(city=”上海”).count()
3
User.objects.all().annotate(city_num=Count(“city”)).values(‘city_num’)
4
mysql> SELECT city,count(id)FROM user GROUP BY city ORDER BY count(id) desc;
+——–+———–+
| city | count(id) |
+——–+———–+
| 上海 | 2 |
| 杭州 | 1 |
| 苏州 | 1 |
+——–+———–+
ret=User.objects.all().annotate(c=Count(‘city’)).order_by(‘c’).reverse().values(‘city’,’c’)
res = models.City.objects.all().values(“city”,”count”).order_by(“count”).reverse() print(res)
5
userlist = [{‘id’:’1’,’name’:’张三’},{‘id’:’2’,’name’:’李四’},{‘id’:’3’,’name’:’王五’}] l = [] for user in userlist: name = user[‘name’] l.append(name) res = “,”.join(l) print(res)

6
二
session 为什么比 cookie安全?
session 是保存在服务端的,cookie 保存在客户端
Session 比 Cookie 更安全吗? 不应该大量使用Cookie吗?
错误。Cookie确实可能存在一些不安全因素,但和JavaScript一样,即使突破前端验证,还有后端保障安全。一切都还要看设计,尤其是涉及提权的时候,特别需要注意。通常情况下,Cookie和Session是绑定的,获得Cookie就相当于获得了Session,客户端把劫持的Cookie原封不动地传给服务器,服务器收到后,原封不动地验证Session,若Session存在,就实现了Cookie和Session的绑定过程。因此,不存在Session比Cookie更安全这种说法。如果说不安全,也是由于代码不安全,错误地把用作身份验证的Cookie作为权限验证来使用
对,我也是这样想。之前说使用cookie不安全,是因为cokkie保存在客户端,可能会被获取到cookie,然后带着cookie直接访问服务端。但是使用seesion的话,虽说数据都保存在服务端,但是你还是要给返回一个cookie,seesion_id吧。那我可以同样拿到session_id值,再去向服务端发请求不久好了吗?

2
不可变的 –> 值传递
可变的 引用传递
5
Django的请求到响应的流程,简单的来说就是利用wsgi,当用户发来一个request进行response,响应前发送request_started信号,经过中间件的process_request,响应完成后会调用中间件的process_response。
6
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。 2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗 考虑到安全应当使用session。 3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能 考虑到减轻服务器性能方面,应当使用COOKIE。 4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。 5、所以个人建议: 将登陆信息等重要信息存放为SESSION 其他信息如果需要保留,可以放在COOKIE中
7

8.


 下午面试碰到的题: 1、实现服务器与业务直接的关系表 用ORm 2、如果实在高并发 3、介绍Restfulmark 4、vue 使用 5、写冒泡排序 6、谈谈并发编程与网络编程 7、什么是消息队列和缓存机制 8、分库分表怎么操作 ,介绍下 9、前后端分离会有什么问题 我说的是跨域问题
下午面试碰到的题: 1、实现服务器与业务直接的关系表 用ORm 2、如果实在高并发 3、介绍Restfulmark 4、vue 使用 5、写冒泡排序 6、谈谈并发编程与网络编程 7、什么是消息队列和缓存机制 8、分库分表怎么操作 ,介绍下 9、前后端分离会有什么问题 我说的是跨域问题
2.http返回状态码(Status-Code), 以3位数字组成
200 # 成功请求
301 # 永久重定向(redirect)
302 # 临时重定向(redirect)
304 # 浏览器缓存
403 # 请求不到首页或权限被拒绝
404 # 请求的资源不存在(找不到文件)
500 # 服务器内部错误,程序代码错误
502 # 找不到后端的资源(后端web连不上)
503 # 响应慢
504 # 请求超时
浏览器跳转–>浏览器缓存–>DNS域名解析–>tcp三次握手–>http请求–>http响应–>tcp四次挥手
http请求
方法:GET 请求
协议:http:// http1.0短连接 http1.1长连接
域名:www.oldboyedu.com
端口:http 80 https 443
路径:/index.php
参数:?user=123&pwd=456
header:(类型、长连接、压缩、语言、浏览器缓存)
空行
http响应:
状态码:
200 304 301 302 401 403 404 500 502 503 504
协议:http1.1
响应主体
django大量用了反射和元类
不同的项目不同的数据库
不同的APP 可以用相同的
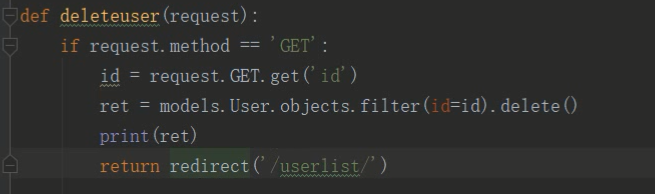
django图书删除原理
1.模板超链接点击
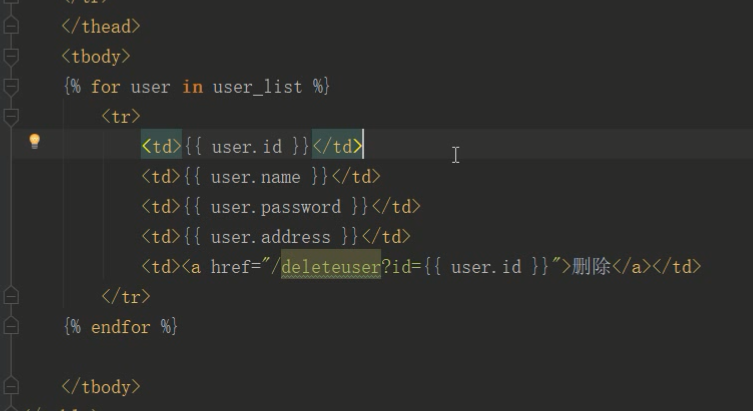
2.视图函数
requset.GET.get(‘key的值’)
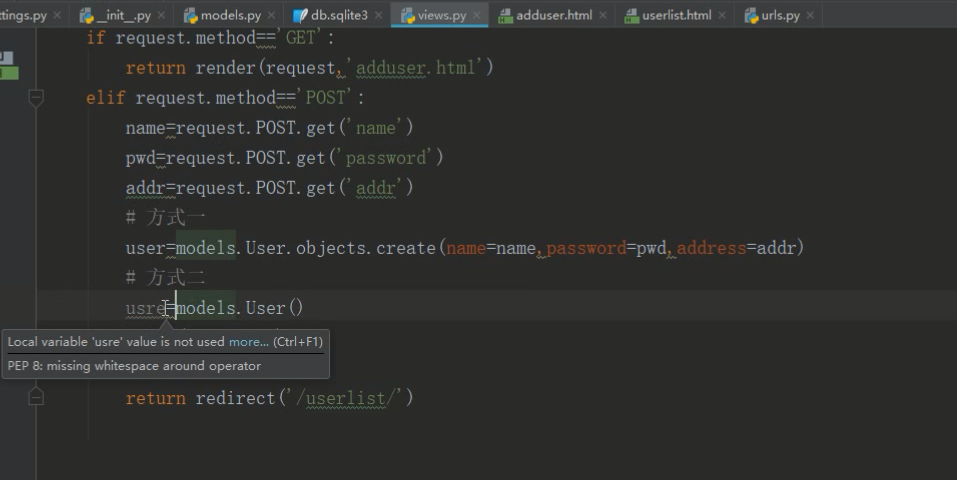
django图书新增原理
先在userlist里面建一个新增超链接

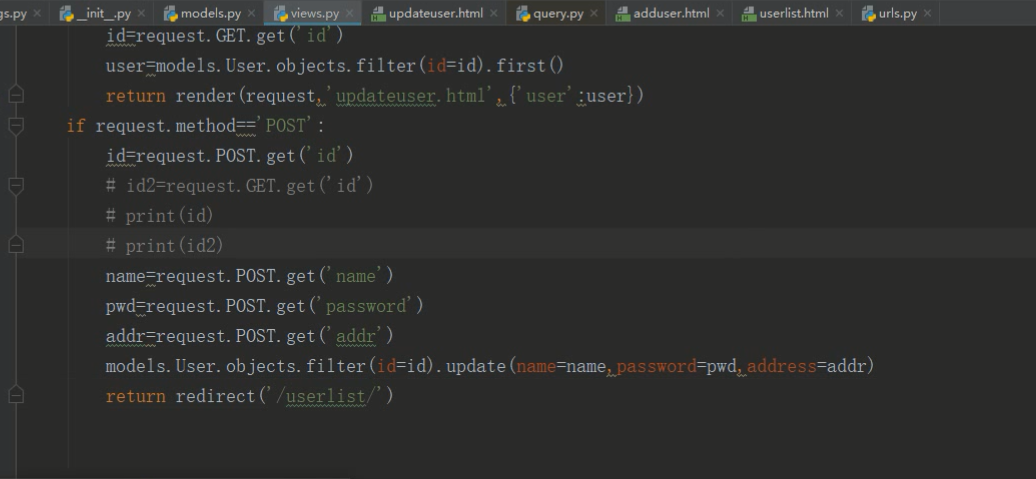
django图书编辑原理
先在模板里面建一个编辑的超链接
传入新的url带id到url后端的view视图函数
然后通过request.GET.get把对应的id拿出来
通过id查出编辑对象返回到模板
但是编辑里面应该有值,所以利用value
最后用requst.POST.get拿到id
最后通过orm查到对应的user对象点update方法进行更新
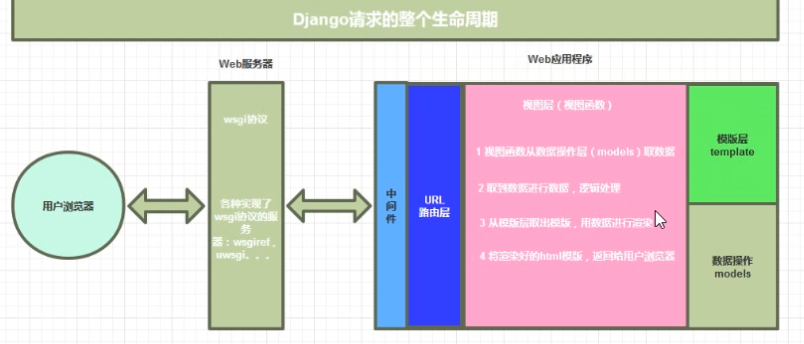
django的生命周期
通过url找到请求的地址找到视图函数,查数据库,拿到模板,把拿到的数据库渲染到模板上



接口与归一化设计
什么是接口
1 | * 1)是一组功能的集合,而不是一个功能 |
为何要用接口
接口提取了一群类共同的函数,可以把接口当做一个函数的集合。
然后让子类去实现接口中的函数。
这么做的意义在于归一化,什么叫归一化,就是只要是基于同一个接口实现的类,那么所有的这些类产生的对象在使用时,从用法上来说都一样。
模仿interface
在python中根本就没有一个叫做interface的关键字,如果非要去模仿接口的概念
可以借助第三方模块:
http://pypi.python.org/pypi/zope.interface
twisted的twisted\internet\interface.py里使用zope.interface
文档https://zopeinterface.readthedocs.io/en/latest/
设计模式:https://github.com/faif/python-patterns
也可以使用继承:
继承的两种用途
一:继承基类的方法,并且做出自己的改变或者扩展(代码重用):实践中,继承的这种用途意义并不很大,甚至常常是有害的。因为它使得子类与基类出现强耦合。
二:声明某个子类兼容于某基类,定义一个接口类(模仿java的Interface),接口类中定义了一些接口名(就是函数名)且并未实现接口的功能,子类继承接口类,并且实现接口中的功能
1 | class Interface:#定义接口Interface类来模仿接口的概念,python中压根就没有interface关键字来定义一个接口。 |
上面的代码只是看起来像接口,其实并没有起到接口的作用,子类完全可以不用去实现接口 ,这就用到了抽象类
1 | 1、类的属性和对象的属性有什么区别?''' |






1 | 装饰器 |










