Scrapy框架
简介
Scrapy是纯Python开发的一个高效,结构化的网页抓取框架;
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。 Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试 Scrapy使用了Twisted 异步网络库来处理网络通讯。
使用原因:
1.为了更利于我们将精力集中在请求与解析上
2.企业级的要求
安装
scrapy支持Python2.7和python3.4以上版本。
python包可以用全局安装(也称为系统范围),也可以安装在用户空间中。
Windows
一.直接安装
- 在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载对应的Twisted的版本文件
- 在命令行进入到Twisted的目录 执行pip install +Twisted文件名
- 执行pip install scrapy
二.annaconda 下安装
安装conda
conda旧版本 https://docs.anaconda.com/anaconda/packages/oldpkglists/
安装方法 https://blog.csdn.net/ychgyyn/article/details/82119201安装scrapy conda install scrapy
Ubuntu 14.04或以上 安装
scrapy目前正在使用最新版的lxml,twisted和pyOpenSSL进行测试,并且与最近的Ubuntu发行版兼容。但它也支持旧版本的Ubuntu,比如Ubuntu14.04,尽管可能存在TLS连接问题。
Ubuntu安装注意事项
不要使用 python-scrapyUbuntu提供的软件包,它们通常太旧而且速度慢,无法赶上最新的Scrapy。
要在Ubuntu(或基于Ubuntu)系统上安装scrapy,您需要安装这些依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
如果你想在python3上安装scrapy,你还需要Python3的开发头文件:
sudo apt-get install python3-dev
在virtualenv中,你可以使用pip安装Scrapy:
pip install scrapy
运行流程
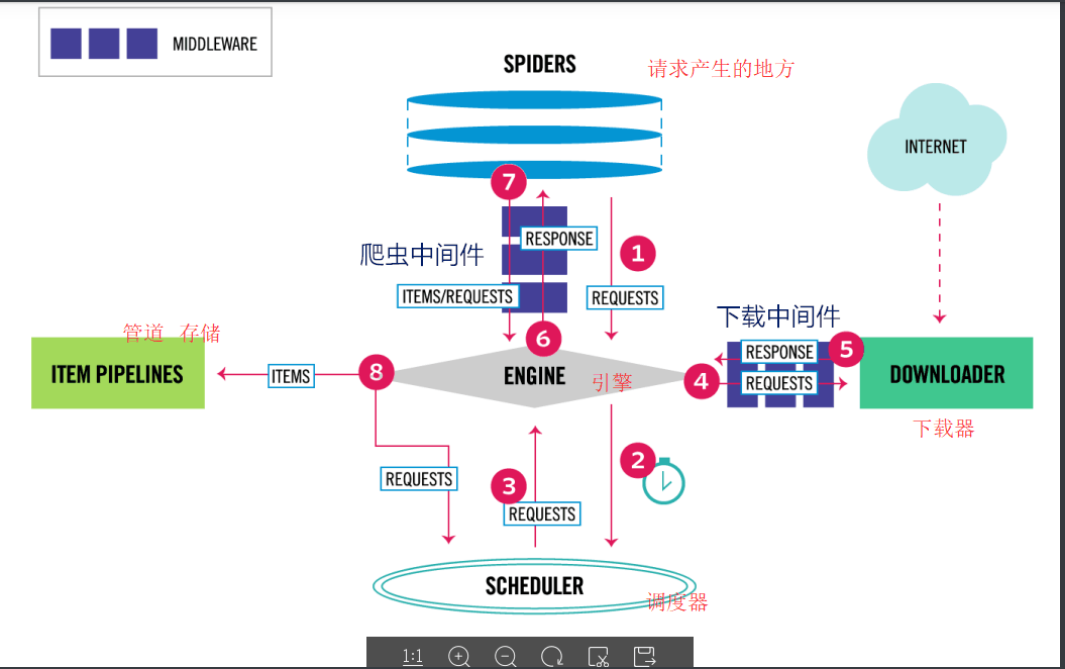
(
spiders网页爬虫
items项目
engine引擎
scheduler调度器
downloader下载器
item pipelines项目管道
middleware中间设备,中间件
)
数据流:
上图显示了Scrapy框架的体系结构及其组件,以及系统内部发生的数据流(由红色的箭头显示。)
Scrapy中的数据流由执行引擎控制,流程如下:
- 首先从网页爬虫获取初始的请求
- 将请求放入调度模块,然后获取下一个需要爬取的请求
- 调度模块返回下一个需要爬取的请求给引擎
- 引擎将请求发送给下载器,依次穿过所有的下载中间件
- 一旦页面下载完成,下载器会返回一个响应包含了页面数据,然后再依次穿过所有的下载中间件。
- 引擎从下载器接收到响应,然后发送给爬虫进行解析,依次穿过所有的爬虫中间件
- 爬虫处理接收到的响应,然后解析出item和生成新的请求,并发送给引擎
- 引擎将已经处理好的item发送给管道组件,将生成好的新的请求发送给调度模块,并请求下一个请求
- 该过程重复,直到调度程序不再有请求为止。
组件介绍
- Scrapy Engine(引擎)
引擎负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件。 - scheduler(调度器)
调度程序接收来自引擎的请求,将它们排入队列,以便稍后引擎请求它们。 - Downloader(下载器)
下载程序负责获取web页面并将它们提供给引擎,引擎再将它们提供给spider。 - spider(爬虫)
爬虫是由用户编写的自定义的类,用于解析响应,从中提取数据,或其他要抓取的请求。 - Item pipeline(管道)
管道负责在数据被爬虫提取后进行后续处理。典型的任务包括清理,验证和持久性(如将数据存储在数据库中) - 下载中间件
下载中间件是位于引擎和下载器之间的特定的钩子,它们处理从引擎传递到下载器的请求,以及下载器传递到引擎的响应。
如果你要执行以下操作之一,请使用Downloader中间件:
在请求发送到下载程序之前处理请求(即在scrapy将请求发送到网站之前)
在响应发送给爬虫之前
直接发送新的请求,而不是将收到的响应传递给蜘蛛
将响应传递给爬行器而不获取web页面;
默默的放弃一些请求 - 爬虫中间件
爬虫中间件是位于引擎和爬虫之间的特定的钩子,能够处理传入的响应和传递出去的item和请求。
如果你需要以下操作请使用爬虫中间件:
处理爬虫回调之后的 请求或item
处理start_requests
处理爬虫异常
根据响应内容调用errback而不是回调请
简单使用
一.项目命令
1.创建项目:
scrapy startproject <project_name> [project_dir]
ps: “<>”表示必填 ,”[]”表示可选
scrapy startproject db
都是db
2.cd 到项目下
scrapy genspider [options]
scrapy genspider example example.com
会创建在项目/spider下 ;其中example 是爬虫文件名, example.com 是 url
 3.运行项目
3.运行项目
scrapy crawl 爬虫文件名 #注重流程
4.setting 里配置 ROBOTSTXT_OBEY;DEFAULT_REQUEST_HEADERS
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’,
‘Accept-Language’: ‘en’,
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36”
}
二.shell 交互式平台
scrapy shell url (start_url) 获取我们项目中的response
测试 xpath进行匹配
项目文件介绍

爬取豆瓣电影
目标数据要求:
- 豆瓣电影250个电影信息
- 电影信息为:电影名字,导演信息(可以包含演员信息),评分
- 将电影信息直接本地保存
- 将电影信息通过管道进行保存
爬虫文件
1 | # -*- coding: utf-8 -*- |
items文件
1 | import scrapy |
piplines文件
1 | import json |
settings文件
1 | # -*- coding: utf-8 -*- |
项目注意事项
- settings文件中 项目默认的是 ROBOTSTXT_OBEY = True,即遵循robots协议,则不能爬取到数据
则更改为 ROBOTSTXT_OBEY = False
- settings中,有些网站需要添加User-Agent ,才能获取到数据 (伪装成客户端)
- settings中,需要将管道打开,才可以将数据传递到pipelines文件中
- items中需要设置相应的字段,使用Item对象传递数据,(可以理解为mysql先定义字段,才能写入数据一样)


