1 | <div id="music163player"> |
索引及执行计划
5.1 索引
1.作用
1 | 1.优化查询 |
5.2 索引的种类(mysql中的一种对象)
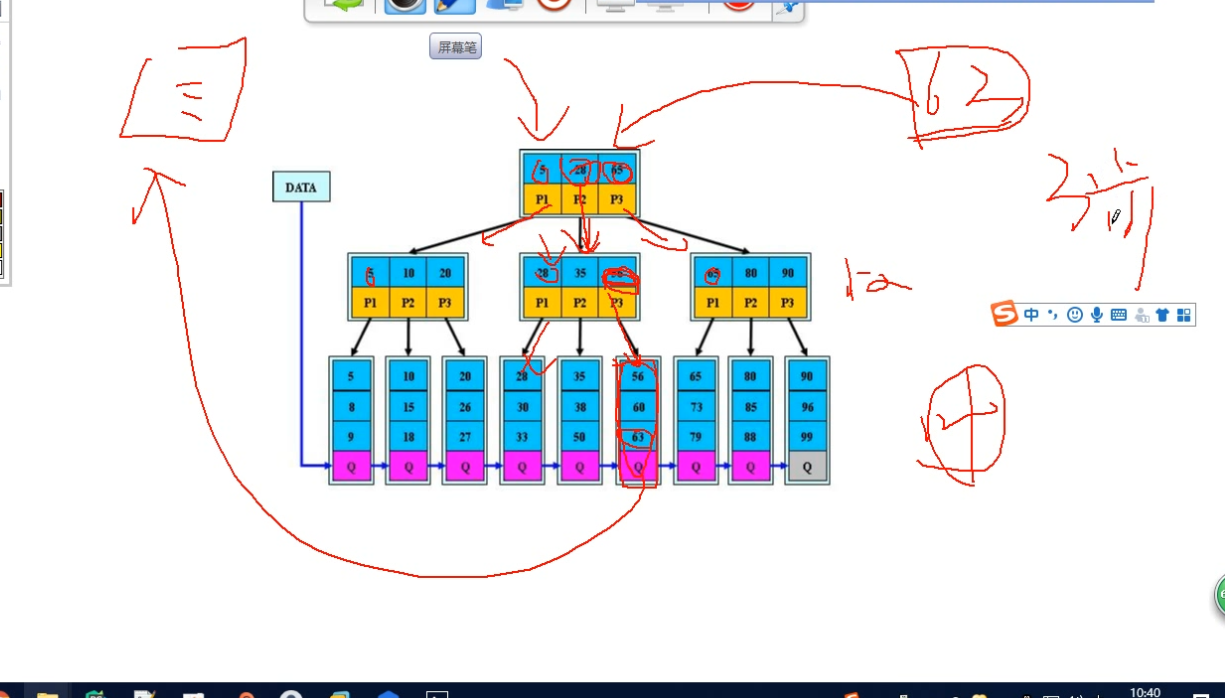
1 | Btree(Btree B+tree B*tree) |
btree
b+tree
b*tree
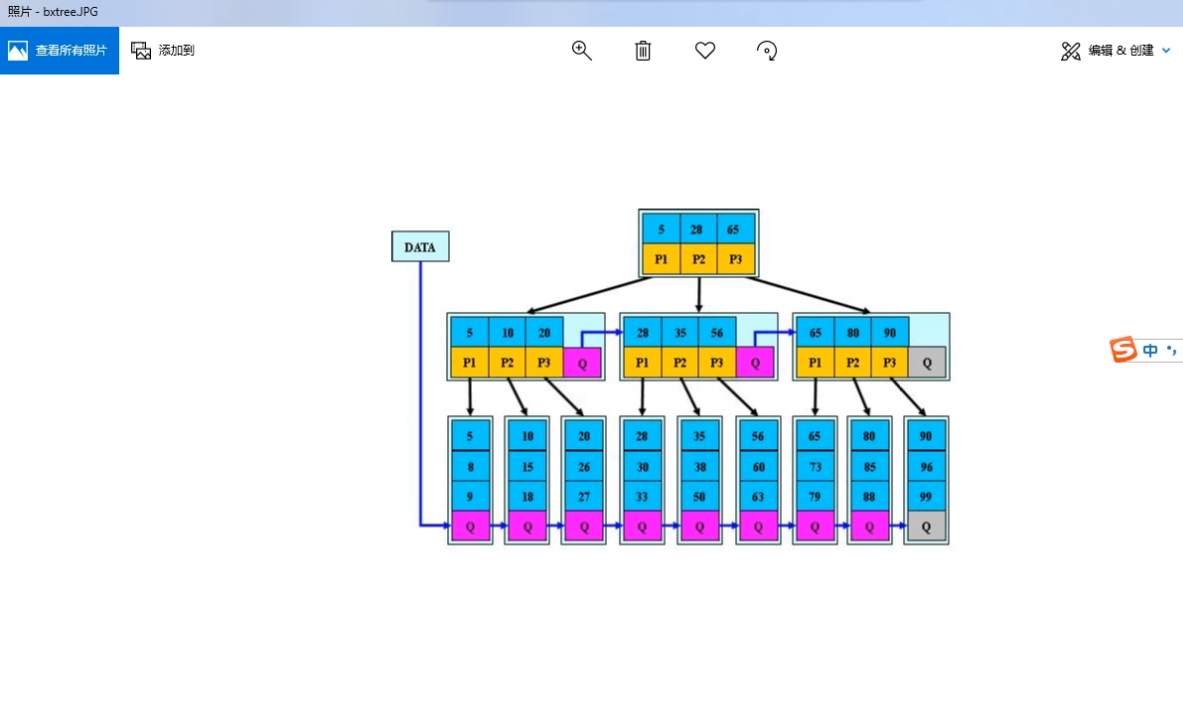
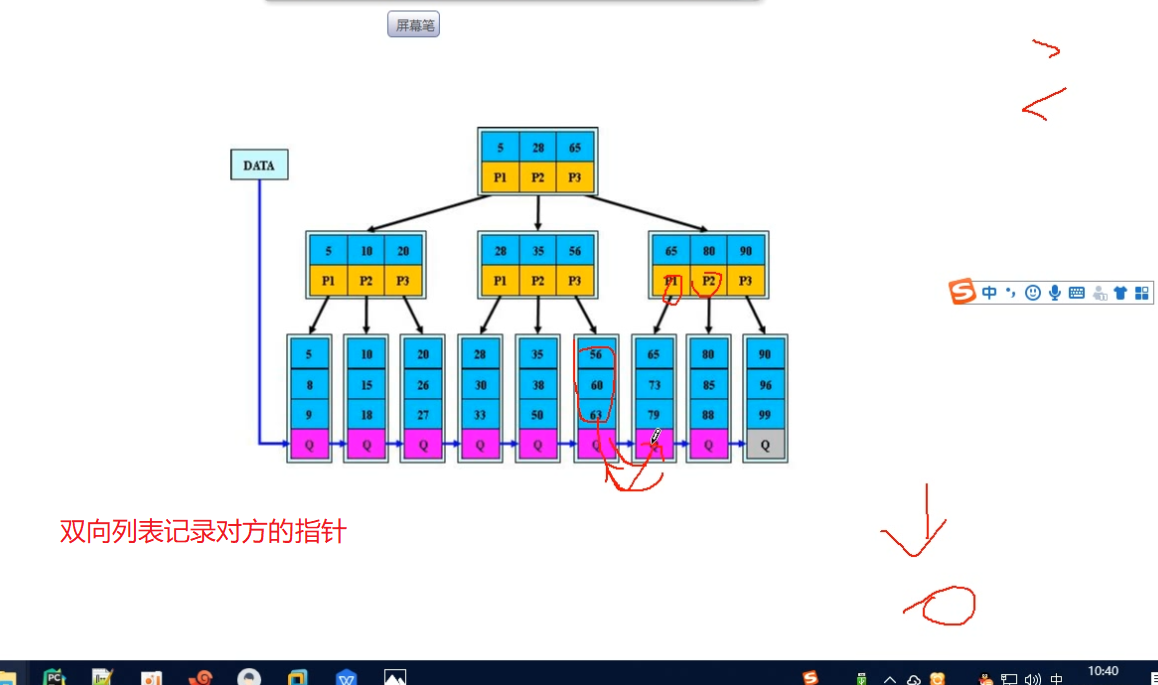
5.3 Btree分类
磁盘叶存储
1.聚集索引:基于主键,自动生成的,一般建表时创建主键,如果没有主键,自动选择唯一键作为聚集索引
1 | 1.会影响数据排列 |
为什么用id做索引
1 | 每个数据页大小是一定的16kb,当数据量越大,当一个数据页装不下时,就会增加枝节点,从而增加B树的层级,影响查询效率。 |
2.辅助索引:人为创建的(普通,覆盖),只存索引键的值
查2此相邻的会快些
1 | 先通过辅助索引,在叶子节点找到辅助索引的值,以及对应的主键 |
5.4 唯一索引:人为创建(普通索引)
1 | 得保证列中的值没有重复 |
5.5 聚集索引和辅助索引的区别
1 | 1.聚集索引:叶子节点,按照主键列的顺序,存 是真正的数据页, |
5.6 索引管理的命令
索引键(key),表中的某一个列
1.普通的辅助索引:mul
1 | 创建索引: |
2.唯一索引:人为创建(普通索引 uni
1 | alter table blog_userinfo add unique key uni_email(email); |
3.覆盖索引:(联合索引)
作用
1 | 作用:不用回表查询,不需要聚集索引,所有查询的数据都从辅助索引中获取 |
bu不要查*,否则覆盖索引无效
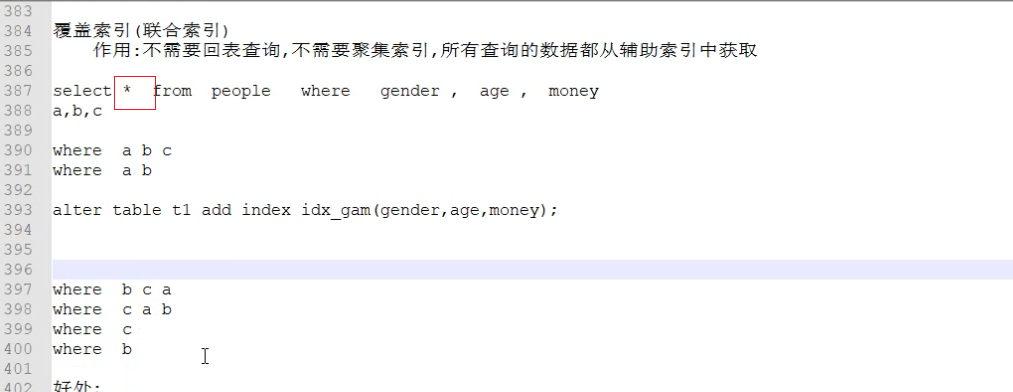
where查的最多的放前面
实例
1 |
|
5.7 索引维护应该注意的地方
大批量插入会锁表
1 | 1.业务繁忙时可能会出现锁表现象 |
注意:实际工作中索引去掉过后,一定要在繁忙时间之前,将索引加上
5.8 如何解决索引导致的插入数据效率低的问题
1.产生的原因
1 | 因为会影响现有的B树的结构,所以插入效率低 |
2.解决方式
1 | 1.降低隔离级别。 |
关闭索引功能
5.9 索引的优化
查询优化神器: explain
1 | 1.索引的合理创建 |
注意: 索引的最高深的优化
1 | 改写sql语句/优化索引 |
6.0 面试可以怎么写
1 | 精通索引的基础优化 |
6. mysql 5.7 初始化配置
6.1 数据库的初始化
1 | mysqld --initialize-insecure --user=mysql --datadir=/data/3307/data --basedir=/opt/mysql |
6.2 配置文件的作用
1 | 1.影响mysqld的启动 |
6.3 如何书写配置文件
1.服务端
1 | [mysqld] ---标签 [server] [mysqld_safe] |
2.客户端
1 | [client] [mysql] [mysqldump] .....标签 |
6.4 一台机器多个实例的架构(3307,3308,3309)
1.创建相关目录
1 | mkdir -p /data/330{7...9}/data |
2.创建每个实例配置文件
1 | vim /data/3307/my.cnf |
3.拷贝
1 | 1.拷贝 |
4.初始化数据
1 | mysqld --initialize-insecure --user=mysql --datadir=/data/3307/data --basedir=/opt/mysql |
5.启动多实例
1 | 1.先授权 |
6.验证:查询一下
1 | netstat -lnp|grep 330 |
7.如何连接多实例(本地方式)
1 | mysql -S /data/3307/mysql.sock |
8.关闭实例
1 | 原始方式 |
9.systemd管理多实例,生成启动脚本
1 | cat >> /etc/systemd/system/mysqld3307.service <<EOF |
10.开机自启动
1 | systemctl enable mysqld3307 |
6.5 隐私相关的操作
注意: 保护公司隐私:不要暴露关键信息
1.设置密码
1 | mysqladmin -uroot -p password 123 |
2.查看数据库已有的用户信息
1 | select user,authentication_string,host from mysql.user; |
6.6 忘记密码如何操作
1.先关闭数据库
1 | /etc/init.d/mysqld stop |
2.关闭连接层:skip-networking关闭远程连接
1 | mysqld_safe --skip-grant-tables --skip-networking & |
3.修改用户表密码
1 | update mysql.user set authentication_string=PASSWORD('456') where user='root' and host='localhost'; |
4.重启数据库
1 | /etc/init.d/mysqld restart |
7.判断优化器是否选择索引
7.1 explain(desc)命令的应用,
获取优化器选择后的执行计划
7.2 使用
1 | explain/desc + 查询语句 |
7.3 信息详解
1 | +----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ |
type:作用
1 | 作用 :1.能够判断是全表扫描还是索引扫描(all就是全表扫描,其他就是索引扫描) |
type:具体类型
1 | 1. all:全表扫描,理论上应该避免全表扫描,具体要看数据量 |
1 | 1.表结构 |
注意:至少是range以上的级别,才能算的上优化
Extra
1 | 注意:filesort 会增加压力 |
优化方案
1 | orderby/ group by /distinct 等会需要排序 |
其他字段意义
1 | possible_keys:可能走的索引 |
7.4 什么是业务
1 | 1. 产品的功能 |
8.建立索引的原则(运维规范)
8.1 建表时一定要有主键,如果相关列可以作为主键,
做一个无关列
8.2 选择唯一性索引
1 | 唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。 |
注意
1 | 主键索引和唯一键索引,在查询中使用是效率最高的。 |
8.3 为经常需要排序、分组和联合操作的字段建立索引
1 | 经常需要ORDER BY、GROUP BY,join on等操作的字段,排序操作会浪费很多时间。 |
8.4 为常作为where查询条件的字段建立索引
1 | 如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此, |
8.5 尽量使用前缀来索引
1 | 如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索 |
8.6 限制索引的数目
1 | 索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。 |
8.7 删除不再使用或者很少使用的索引(percona toolkit)
1 | 表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理 |
8.8 大表加索引,要在业务不繁忙期间操作
9. 不走索引的情况(开发规范)
9.1 没有查询条件,或者查询条件没有建立索引
1 |
|
9.2 查询结果集是原表中的大部分数据,应该是25%以上。
1 | 查询的结果集,超过了总数行数25%,优化器觉得就没有必要走索引了。 |
9.3 索引本身失效,统计数据不真实
1 | 索引有自我维护的能力。 |
9.4 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
1 | 例子: |
9.5 隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误.
1 | 比如 telnum这个字段是varcher类型 |
9.6 <> ,not in 不走索引
9.7 like “%_” 百分号在最前面不走
1 |
|
注意: %linux%类的搜索需求,可以使用elasticsearch 专门做搜索服务的数据库产品
9.8 单独引用联合索引里非第一位置的索引列.作为条件查询时不走索引.
1 | 列子: |
10. 压力测试
10.1 模拟数据库数据模拟数据库数据
1 | 为了测试我们创建一个oldboy的库创建一个t1的表,然后导入50万行数据,脚本如下: |
10.2 检查数据可用性
1 | mysql -uroot -p123 |
10.3 在没有优化之前我们使用mysqlslap来进行压力测试
1 | mysqlslap --defaults-file=/etc/my.cnf \ |
11. mysql的存储引擎
11.1 作用
1 | 真正和磁盘数据打交道的 |
11.2 innodb存储引擎简介
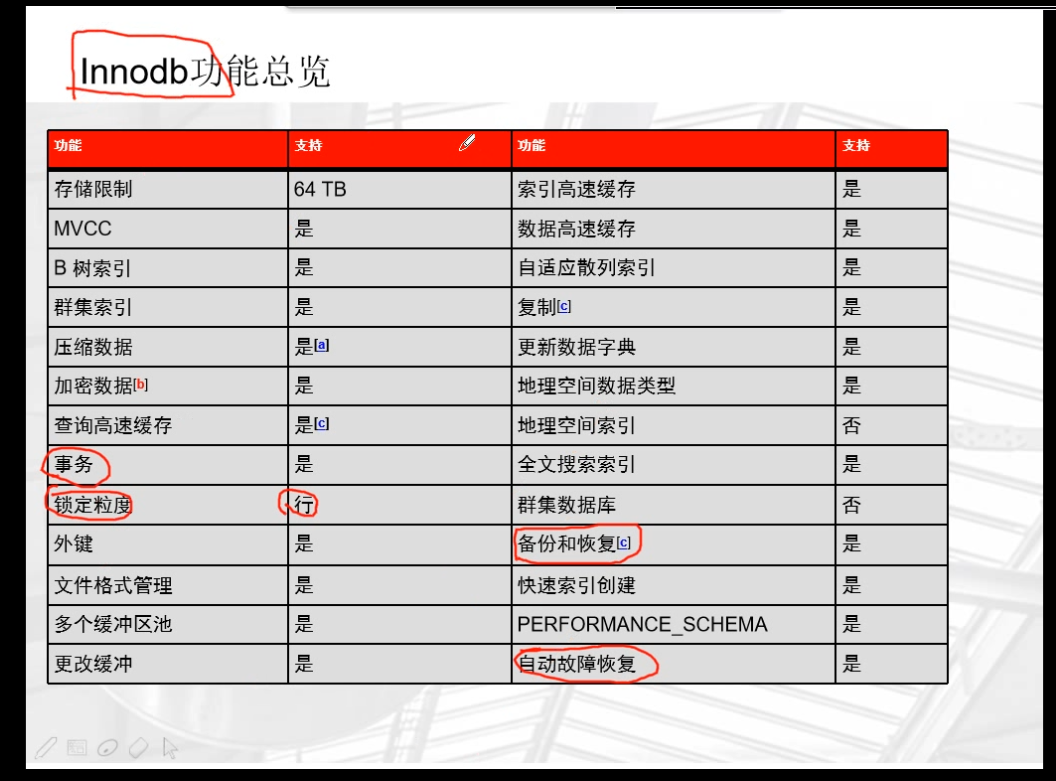
1.实际存储的文件格式
1 | ibd文件: 存储表的数据行和索引 |
11.3 myisam存储引擎简介
1.实际存储的文件格式
1 | frm文件: 表结构相关信息 |
11.4 innodb的核心特性:事务、行锁定粒度,备份和恢复,自动故障修复
1.事务的作用:保证交易的完整性
2.事务的特性:ACID
1 | 1.atomic(原子性) |
**注意:
1 | 1. |

11.5 mysql的隔离级别
1.RU:读未提交 脏读(没有提交的数据)/不可重复读/幻读
1 | 1.定义:就是一个事务可以读取另一个未提交事务的数据。 |
2.RC:读已提交 不可重复读/幻读
1 | 1.定义:就是一个事务要等另一个事务提交后才能读取数据。 |
3.RR:可重复读 不会出现幻读,查询的数据都是一样的
1 | 1. 就是在开始读取数据(事务开启)时,不再允许修改操作 |
1 | 幻读实例: |
4.S:可串行,序列化
1 | 定义:在事务操作期间,禁止其他事务进行更新,插入,删除等操作 |
11.6 事务的控制语句
1 | 正常 |
11.7 隐式提交:(默认方式)
1. 设置关闭默认提交
1 | 1.当前会话生效 |
2. 例子
1 | 1.例子一: 一个事务中有多个事务开启 |
12. 日志
12.1 错误日志
1 | log_error=/var/log/mysql.log |
12.2 二进制日志
1.作用
1 | 1.记录所有变更类的语句 |
2.配置方法
1 | log_bin = /opt/mysql/data/mysql-bin |
3.row模式和statement模式区别
1 | insert into tq values (now()) |
4.查看日志
1 | show binary logs; ---查看 |
5.内容查看
1 | 1.按事件查看日志内容 |
6.截取二进制命令
1 | mysqlbinlog --start-position=219 --stop-position=186613 /opt/mysql/data/mysql-bin.000012 >/tmp/binlog.sql |
12.3 慢日志:记录慢语句的日志;默认情况下是没有开启这个功能–需要手动开启
1.如何开启:配置文件中添加
1 | slow_query_log=1 |
2.时间维度
1 | long_query_time = 1 |
3.索引维度:判断没有走索引的语句
1 | log_queries_not_using_indexes=1 |
13. 备份恢复
13.1 备份的分类
1 | 逻辑备份:sql语句的备份 做迁移的很好的工具 |
13.2 逻辑备份工具介绍
1.工具一
1 | select xxxx from t1 into outfile '/tmp/redis.txt' |
2.工具二
1 | mysql -uroot -p123 -e "select concat('hmset city_',id,' id ', id,' name ',name,' countrycode ',countrycode,' district ',district,' population ',population) from world.city limit 10 "|redis-cli |
13.3 mysqldump的使用和参数
1.参数:基本参数
1 | mysqldump |
2.参数:其他参数
1 | -A 全库备份 |
1 | 1.完整实例 |
14. 主从复制:基于二进制日志实现的
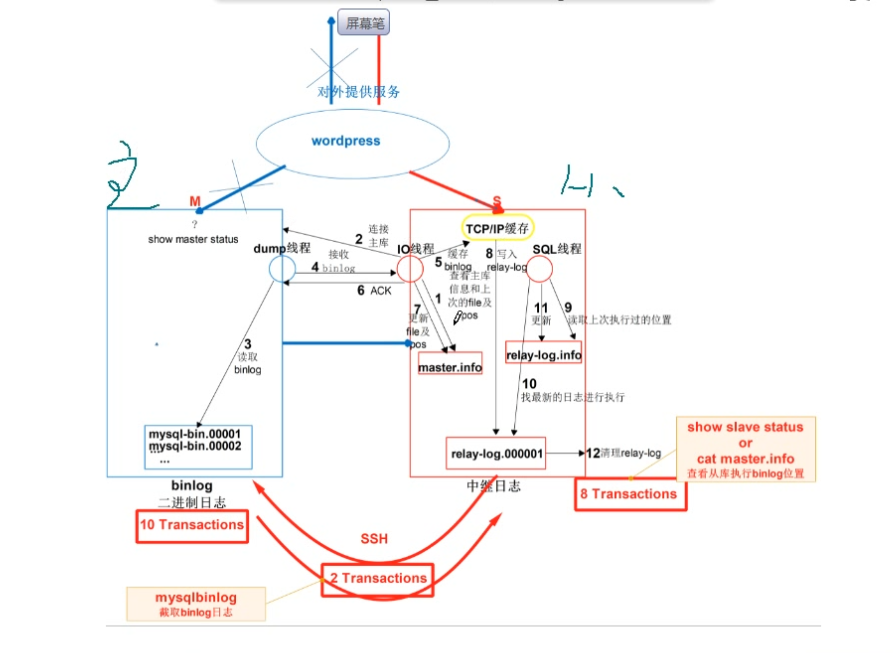
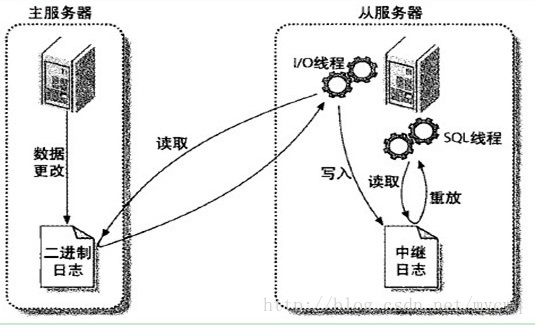
14.1 为什么要有主从复制
1 | 单纯的备份恢复,要耗费大量的时间 |
14.2 主从复制的核心:读写分离
(读多写少 -适合– 读写分离)
14.3 模拟主从复制功能
1.前提
1 | 1.以mysql实例3307作为主库,以3308作为从库 |
- 主库3307中创建复制用户
1 | 1.主库开启二进制日志 |

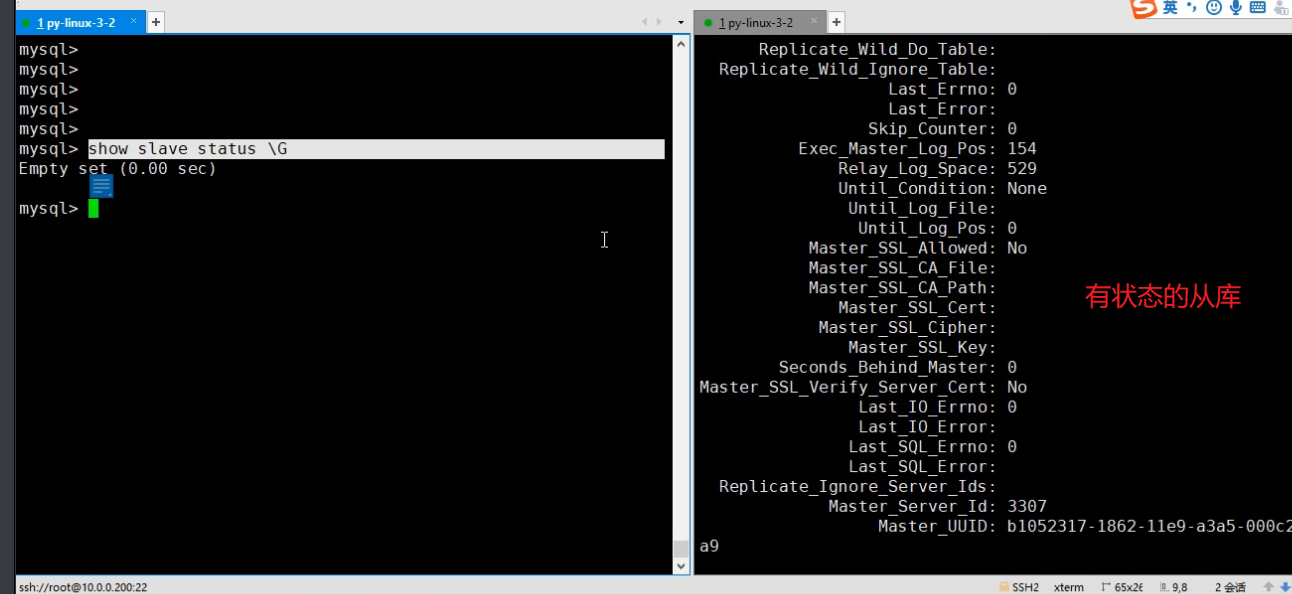
- 从库3308节点开启主从复制功能
1 | 1.进入从库的mysql |
加中间件
15. mysql高可用架构(安全性)
15.1 “高可用”架构
1 | 99% 1%*365=3.65D = 87.6h |
注意:没有百分百高可用的架构
15.2 MySQL高可用架构介绍
1 | 1.MHA------------自愈性的架构,分钟内完成自愈 |
16. 高性能架构(安全性+高性能)
16.1 基本概念
1 | 分布式架构 |
16.2 目前主流的读写分离架构
1 | 1.atlas 360 C++ |
16.3 目前主流的分布式架构
1 | 分片集群 |


